Release Note
・
Announcement
Pruna 0.3.2: More OSS Algos, More Ways to Optimize

Minette Kaunismäki
DevRel Engineer

Begüm Çig
ML Research Engineer

Gaspar Rochette
ML Research Engineer

Sara Han Díaz
DevRel Engineer

Bertrand Charpentier
Cofounder, President & Chief Scientist

It’s been almost a year since we open-sourced. Over that time, Pruna has grown quickly: more contributors, algorithms, families, tutorials, and optimized models. With v0.3.2, open-sourcing many more of these algorithms is the natural next step.
What Landed in 0.3.2
This release expands the ecosystem with support for a broad set of new algorithms and new algorithm families, improved compatibility across them, and a set of fixes that make the whole framework stronger.
New algorithms and families: Pruna 0.3.2 adds a broad new set of optimization building blocks to the OSS stack. This includes new compilers, kernels, pruners, and entire new algorithm families such as Decoders, Distillers, Enhancers, and Recoverers.
More than just new algos: The most important part of this release is not only the number of new algorithms, but how they fit into Pruna. 0.3.2 increases composability by allowing otherwise incompatible algorithms to be treated as compatible when they are applied to disjoint parts of a model.
More tutorials: The new release also brings more tutorials to help you make your model more efficient. So it makes it easier for you to discover what each method does, understand when to use it, and get started composing them in practice.
Pruning bugs and maintenance: This release is not only about new features, but it also includes important fixes and cleanup work that reinforce the core of Pruna. That includes pruning-related bug fixes, maintenance work across the codebase, and general improvements that make the new algorithms easier to use and more reliable in practice.
For more information, check the GitHub release here.
Meet the New Algorithms and Families
One of the biggest updates in 0.3.2 is the expansion of Pruna’s optimization core.
Expanding Existing Families
These new compiler integrations expand the set of execution-level optimizations. You can use ipex-llm for PyTorch-based LLM inference on Intel CPUs and x-fast to speed up inference for any model using a combination of xformers, triton, cudnn, and torch tracing.
This release introduces two important kernel-level additions. Ring attention brings distributed attention capabilities that help scale workloads across multiple devices, while sage attention adds a fast, memory-efficient attention kernel to the toolbox.
Pruner: padding_pruning
Padding pruning allows you to remove unnecessary padded computation. This is a targeted optimization that, while simple, still brings wins in efficiency.
Introducing New Families
Decoders: zipar
Pruna now supports decoders to speed up autoregressive generation by changing the decoding strategy itself. These methods speed up autoregressive generation by making decoding more parallelizable.
Distillers: text_to_image_distillation_inplace_perp, text_to_image_distillation_lora, text_to_image_distillation_perp, hyper
Distillers make it easier to reduce inference cost by transferring behavior into smaller or more efficient variants.
Enhancers: img2img_denoise, realesrgan_upscale
Enhancers improve output quality after or alongside optimization. These methods are especially useful when the goal is not only faster inference, but also better final outputs.
Recoverers: text_to_image_distillation_inplace_perp, text_to_image_distillation_lora, text_to_image_distillation_perp, text_to_image_inplace_perp, text_to_image_lora, text_to_image_perp, text_to_text_inplace_perp, text_to_text_lora, text_to_text_perp
Recoverers make it possible to push compression more aggressively and then restore part of the lost quality afterward. This gives you a much more flexible optimization workflow, especially when combining quantization, pruning, or distillation with quality recovery steps.
More Efficient Strategies
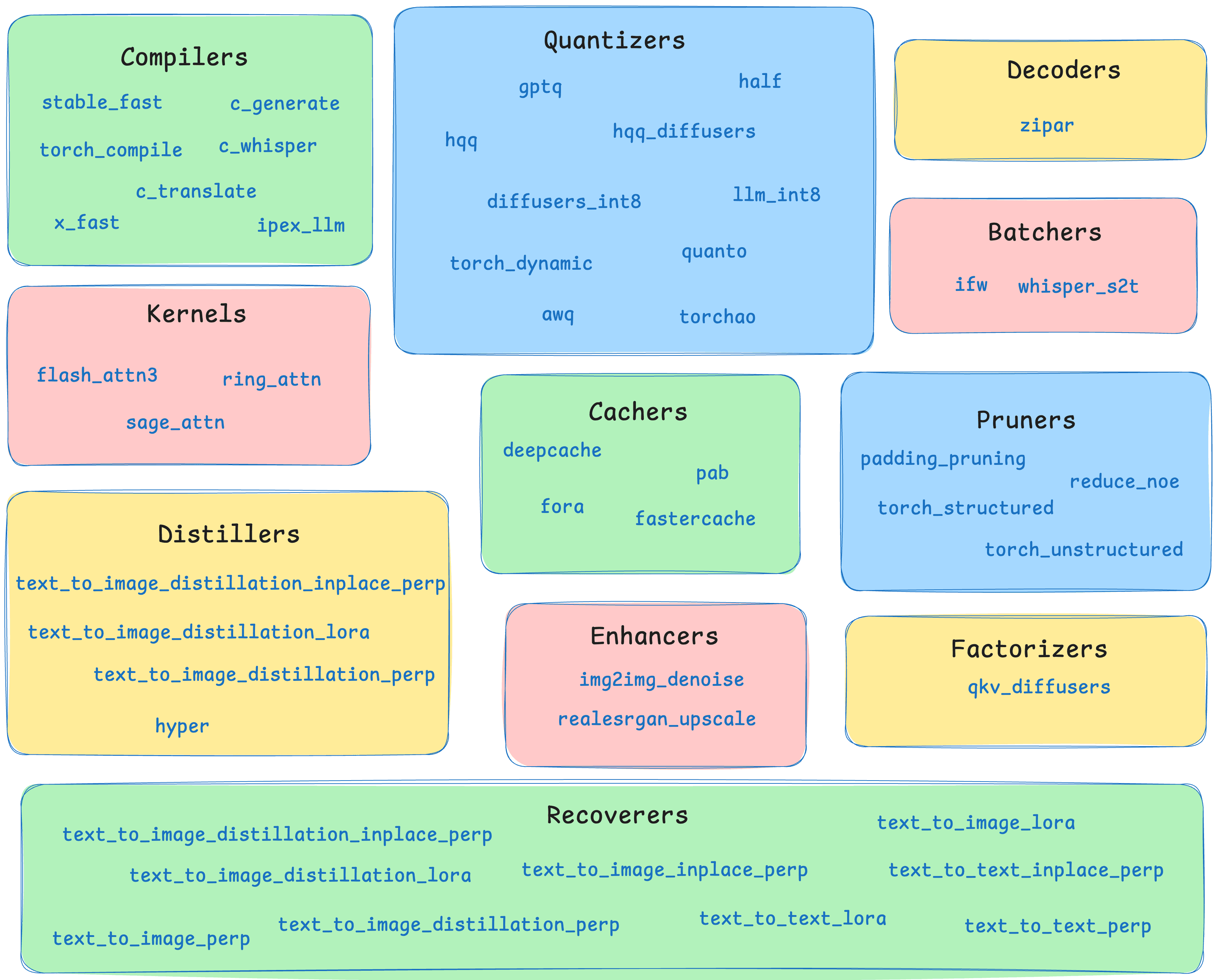
Diagram showcasing the current algorithm families supported by Pruna (10-03-2026)
So, instead of only asking “how do I make this model faster?”, you can now think in more advanced strategies like:
Compress first, then recover quality
Parallelize decoding instead of just reducing precision
Distribute attention across devices
Add post-processing quality enhancers
Swap in better attention kernels
Combine multiple compatible algorithms into a single pipeline
This makes Pruna more flexible not just as a collection of optimizations, but as a system for combining them easily.
Try out Pruna 0.3.2, smash your model, and show us what combinations you come up with.
Enjoy the Quality and Efficiency!
Compress your own models with Pruna and give us a ⭐️ to bring you many more algos!
Stay up to date with the latest AI efficiency research on our blog, explore our materials collection, or dive into our courses.
Join the conversation and stay updated in our Discord community.
・