Announcement
The 2025 Pruna’s Recap

Sara Han Díaz
DevRel Engineer

Bertrand Charpentier
Cofounder, President & Chief Scientist

As the year comes to a close, it’s time to take a moment and look back at what we shipped, what we learned, and what we built alongside our community. And honestly—2025 didn’t slow down:
We opened up more of our work to the open-source world.
We pushed hard to build and optimize models.
We doubled down on educating around AI efficiency.
And (best of all), we grew our team and community, and spent real time with the people in it.
So here are the highlights that made this year one to remember.
Making More Efficient Models
Building Performance Models. One of the things we’re very proud of this year is our performance models: our own optimized models that we host and serve.
In December 2025, we launched P-Image and P-Image Edit, our “go-to” for teams that want results fast without burning budget, thanks to their sub-second speed and ultra-low cost without sacrificing quality. Moreover, they have excelled in prompt adherence, text rendering, and multi-image editing, offering high control for multi-image editing.
Another example is our Wan Image model. Starting from the video models Wan-2.1 first, and Wan 2.2 later, we wondered how we could keep the quality while dropping the “video overhead”. As a result, we got stunning outcomes, generating 2MP consistent and cinematic images in 3.1 seconds.

Optimizing Any Model. This year wasn’t only about building efficient models—we also optimized nearly 40 endpoints overall. We were backed by multiple inference providers, which helped us scale this work into something people can rely on in real-world deployments. The idea was simple: take well-known models, optimize them like crazy for speed, efficiency, and cost, and make them easy to use in production.
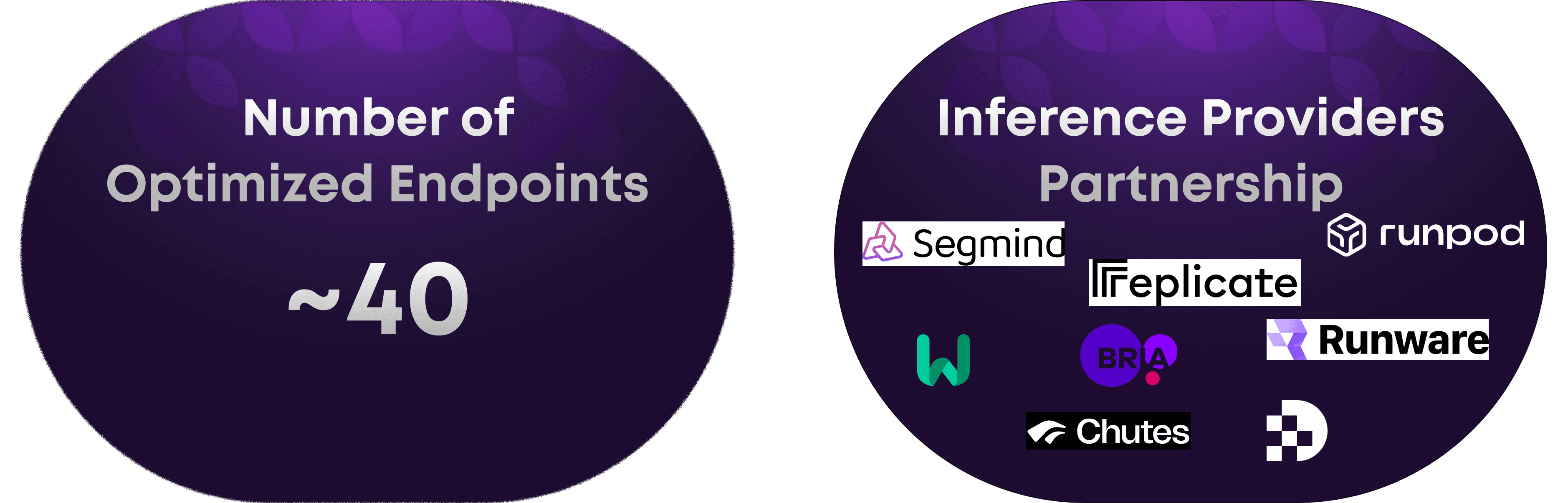
Making AI Accessible. In 2025, accessibility wasn’t a slogan for us—it was a measurable outcome. By making models faster and cheaper to run, we enabled people to try, use, and ship with models that would have been otherwise out of reach. Less latency means better user experience, and lower inference costs mean more room to experiment, iterate, and deploy at scale.
Across all the models optimized with Pruna this year, those gains added up to real-world impact: thousands of hours not spent waiting on slow inference, and millions of dollars not burned on unnecessary compute. This is what accessibility looks like in practice—AI that more teams can afford, operate, and rely on in production.

Making AI Sustainable. At Pruna, sustainability has always been a mission for the team. So this year we tried to put real numbers behind the impact of what we do.
We made an estimate of the energy and CO₂ we’ve avoided by comparing our optimized models against their base versions—basically, the difference between what would’ve been consumed if we hadn’t optimized anything vs. what’s actually been needed with Pruna.
Here’s what the math says we saved:

AI Efficiency isn’t just about speed or cost—it’s one of the most practical ways to make AI more sustainable.
Building in the Open
Open-sourcing the AI optimization framework. March 2025 was a big milestone for us: we went open-source with our own package—the Pruna package—built to make models faster, smaller, cheaper, and greener. The goal was about empowering developers and researchers with an easy-to-use package that integrated state-of-the-art compression methods to deliver maximum efficiency, along with an easy way to evaluate the optimization gains.

Educating about AI efficiency. And because shipping tools isn’t enough, we also leaned hard into education this year. We put real effort into making AI efficiency approachable, not just for researchers, but for the engineers who have to ship things in the real world. That’s why we created our AI Efficiency Course, published many blogs with practical breakdowns, and built the awesome repository of resources to help teams understand the why behind optimization (cost, latency, sustainability, scalability), and the how (what techniques to use, what trade-offs to watch for, and how to measure impact properly).

Thanks to the community, we’ve grown fast this year—and it’s been one of the most energizing parts of 2025. One standout moment was joining Hacktoberfest, where the community worked together to solve dozens of issues.
So, this is also the time to thank you all of you. We’re lucky to build this in the open with you, and we’re excited to keep growing together in 2026.
Benchmarking, Not Assuming
You can’t “vibe check” performance; you have to measure it. That’s why we built Inferbench—a leaderboard to compare the performance of different text-to-image providers.
The reason? A lot of providers run “the same model,” but under the hood, they can be doing very different things… and they don’t always say what’s happening in the background. The result is that two endpoints with the same model name can deliver very different real-world performance. So we made the comparison as fair as possible by keeping the generation setup consistent across providers. To round it out, we also paired the speed/cost results with automatic quality metrics, so it’s not just “fast vs. slow,” but a real view into the trade-offs (and where you don’t actually need to trade off at all).
Stay tuned, new updates coming in 2026!
Growing the Community
One thing we’ve tried really hard to do (even while moving fast) is stay close to the people building with us and stay in the loop on what’s happening across the AI landscape.

This year, we joined, sponsored, and participated in a bunch of conferences—getting inspired, sharing what we’re building, and having those revelation chats. For instance, we attended the RAISE Summit, AI Engineer Conference, and VivaTech, and also created our workshop for the dotAI conference, or had our booth and merch in NeurIPS (we ran out of snacks!).

But it wasn’t just conferences. We also wanted to be more in touch with the community, so we hosted the AI Efficiency meetups in Paris and Munich, where we met many of you, and made things accessible online with research and cloud providers' webinars.
All the sessions were really enjoyable, and we were lucky to have some great guests join us and share their work: Benoit Petit from Hubblo, Ekin Karabulut from Run AI, Clément Moutet from Vikit.ai, James Martin from Better Tech, Oussama Kandakji from AWS, Jules Belveze from Dust, Thomas Pfeil from Recogni, Svetozar Miucin from AWS, Morith Thüning from Tenstorrent, Lukas Rinder from Tensordyne, Léah Goldfarb from ESG, Sean Miller and Shawn Rushefsky from Salad, Yann Léger from Koyeb, Hicham Badri from Mobius Labs or Christopher De Sa from the Cornell University, we will always thank.

Expanding the Team
One of our goals is to keep growing together, and in 2025, new people joined the team with full energy and new insights.

We also put effort into building a culture where we can collaborate comfortably and trust our teammates. So, we added GatherTown as our little virtual office for meetings, staying connected throughout the day, and solving a crime case during the Christmas party? We also managed to get together for an offsite in Strasbourg, which is always the best way to keep in touch.

And last but not least, we had fun together!

What’s coming for 2026
2025 was a big year, and honestly, we don’t expect 2026 to slow down. We shipped, learned, and kept moving even when things got tough. So, we’re really proud of what we managed to build and even more excited about where it’s heading, because yes, we’re cooking up new things for next year.
Thanks for being part of the journey this year. Enjoy the end of the year, and we’ll see you in 2026.
Enjoy the Quality and Efficiency!
Want to take it further?
Compress your own models with Pruna and give us a ⭐ to show your support!
Try our endpoints in Replicate, Wiro, Segmind, Runware with just one click.
Stay up to date with the latest AI efficiency research on our blog, explore our materials collection, or dive into our courses.
Join the conversation and stay updated in our Discord community.
・