Technical Article
vLLM Supercharged: Pruna’s Quantization Boost on H100

Louis Leconte
ML Research Engineer

Bertrand Charpentier
Cofounder, President & Chief Scientist

Over the past years, the LLM ecosystem has seen vLLM emerge as one of the most efficient inference engines. At Pruna, we've been pushing this further by integrating advanced quantization techniques into vLLM, delivering faster inference and improved hardware utilization. Building on our work with LLaMA-8B in Llama Juiced, we present fresh results focused exclusively on vLLM, benchmarked on an H100 GPU. While the previous blog explored different ways of running inference with LLMs (using transformers, TritonServer, and vLLM), this blog presents advanced results focusing on vLLM serving. Our contributions are built on top of vLLM (hence compatible with other techniques, such as continuous batching and speculative decoding) and provide reductions of between 1.2x and 1.5x in time to first token and inter-token latency metrics.
Quantization as the Key Ingredient
Our improvements come from layered quantization strategies:
Pruna: This OSS method is based on the popular bitandbytes (a widely used 4/8-bit quantization) package.
Pruna Pro - Option 1: This feature is powered by HQQ, a high-quality quantization approach that balances speed and accuracy, and is already available in pruna_pro
v0.2.10.Pruna Pro - Option 2: This is our latest vLLM work, featuring Higgs. It is optimized for latency-sensitive production workloads and will be available in pruna_pro in October 2025.
We’ve detailed the math behind these methods in our quantization deep dive. Here, we show how they concretely impact vLLM performance. The goal is not to replace the popular vLLM with a custom serving engine. The goal is to build on top of vLLM, and the user just has to run pip install pruna (or pruna_pro) to enjoy the speedups! Detailed tutorials are provided here (for pruna) and here (for pruna_pro).
Inter-Token Latency (ITL): Scaling with Batch Size
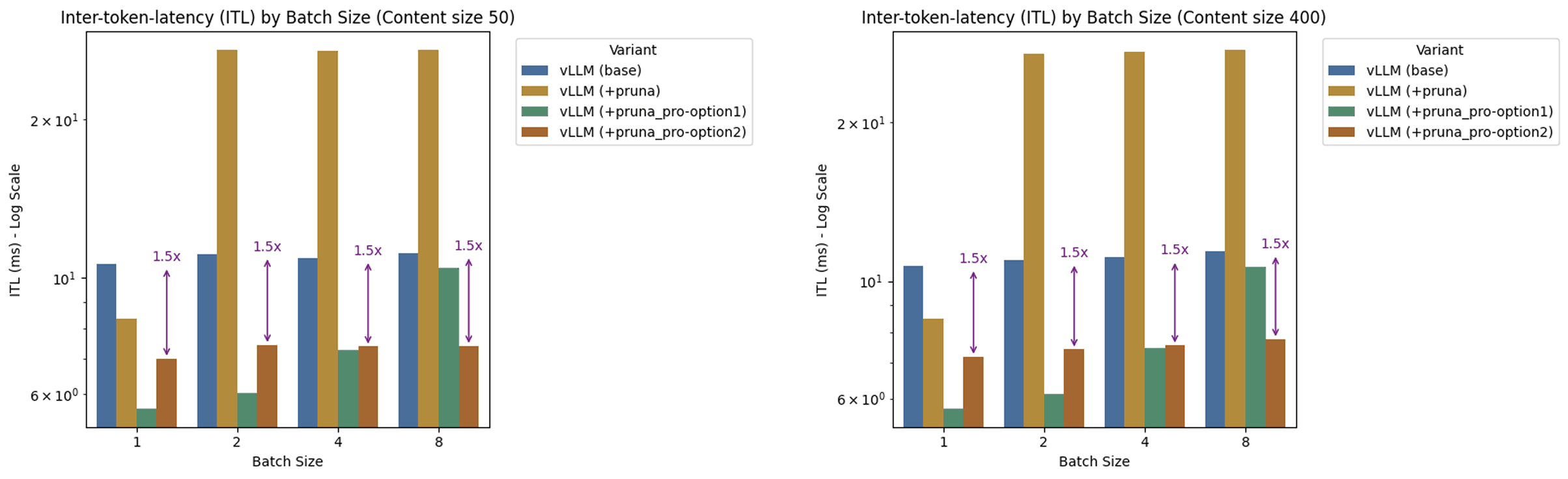
What we can see:
Base vLLM sits at ~11–12 ms per token.
Pruna provides ~1.2x gain at single batch inference, but struggles at higher batch sizes.
Pruna Pro - Option 1 achieves the lowest ITL, consistently improving throughput by up to 2× for some batch sizes.
Pruna Pro - Option 2 follows closely behind HQQ, but maintains a stable and impressive 1.5x speedup even at batch size = 8.
Takeaway: Pruna Pro maintains stable latency with larger batch sizes, ensuring production systems can scale without degrading response times. This is especially critical for serving many concurrent users.
Time-To-First-Token (TTFT): Speeding Up Responsiveness
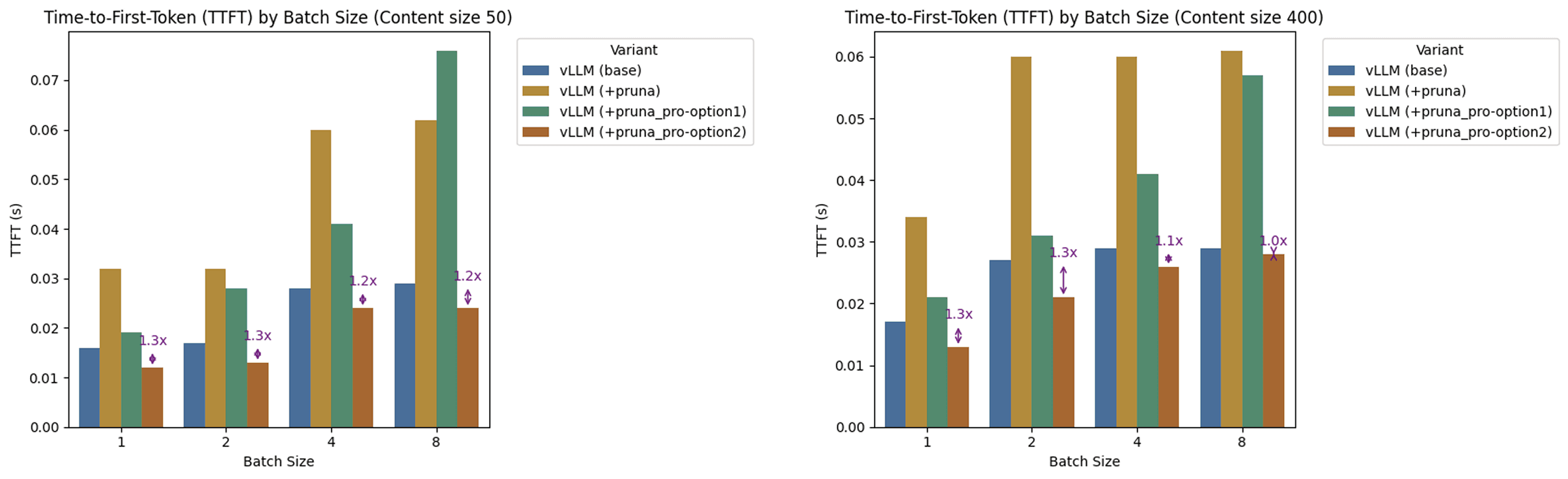
What we can see:
Base vLLM achieves ~25–30 ms TTFT.
pruna_pro - Option 1 presents a time to first token that is slightly higher than the base vLLM.
pruna_pro - Option 2 closes the gap with vLLM on large batch size, and can deliver up to 1.3x speedup on smaller batch sizes.
Takeaway: By cutting TTFT at low batch sizes, Pruna makes chat-style interactions feel snappier—a crucial advantage for latency-sensitive applications like copilots and assistants.
Why This Matters
On H100, Pruna’s quantizations make vLLM substantially faster and more scalable. Relative to base vLLM’s ~80–90 tokens/s, Pruna Pro - Option 1 consistently delivers ~130–170 tokens/s across batch sizes, while Pruna Pro - Option 2 is close behind at ~140–150 tokens/s. Coupled with 1.2–1.3× lower TTFT, the Pro stack makes chat experiences snappier and sustains higher concurrency, translating directly to better GPU utilization and lower serving costs.
Production-grade efficiency: Enterprises running large-scale LLM deployments gain both higher throughput and faster responses.
Smooth batch scaling: Unlike traditional quantization approaches, pruna_pro remains stable at high batch sizes, unlocking cost-efficient inference.
Memory headroom: By shrinking weight representation, quantization frees GPU memory, enabling larger models, bigger batch sizes, or longer contexts on the same hardware. This can reduce GPU footprint in production.
Sustainability bonus: With fewer GPUs needed and shorter inference times, quantization reduces energy per token, driving both lower costs and a smaller carbon footprint at scale.
Takeaway: The main story is speed and scalability—but the side benefits of memory efficiency and sustainability compound into real-world impact, making quantized vLLM with Pruna not just faster, but also leaner and greener.
Accuracy: Minimal Trade-offs for Major Gains
Quantization inevitably raises the question of accuracy preservation. Our benchmarks across MMLU, GSM8k, and Wikitext2 perplexity show that Pruna’s methods maintain competitive results:
base | Pruna Pro - Option 1 | Pruna Pro - Option 2 | |
|---|---|---|---|
MMLU(%) | 68.64 | 66.84 | 66.82 |
gsm8k (%) | 79.98 | 72.71 | 75.21 |
Wikitext2 (ppl) | 8.64 | 9.17 | 9.19 |
On MMLU, the original model scores 68.64%, while Pruna Pro - Option 1 and Pruna Pro - Option 2 remain close at 66.8%.
For GSM8k, the original achieves 79.98%. Pruna Pro - Option 1 drops to 72.7%, while Pruna Pro - Option 2 recovers much of the performance at 75.2%.
On Wikitext2, perplexity rises only slightly from 8.64 (original) to ~9.2 under quantization.
Takeaway: The performance drop is marginal relative to the gains in throughput, memory, and ecological efficiency. Notably, Pruna Pro - Option 2 narrows the gap compared to Pruna Pro - Option 1, indicating that our upcoming quantization engine is further aligning efficiency with accuracy.
Enjoy the Quality and Efficiency!
vLLM has already set a new standard for inference. With Pruna quantizations layered on top, we're showing that latency and scalability can be further improved without sacrificing model accuracy.
For teams deploying at scale, Pruna Pro unlocks the sweet spot: faster responses, stable ITL under load, and efficient GPU utilization. And we're just getting started—stay tuned ;)
Want to take it further?
Compress your own models with Pruna and give us a ⭐ to show your support!
Try our Replicate endpoint with just one click.
Stay up to date with the latest AI efficiency research on our blog, explore our materials collection, or dive into our courses.
Join the conversation and stay updated in our Discord community.
・