Technical Article
Quantized LLMs on edge devices: Techniques and Challenges

Amine Hamouda
ML Working Student

Bertrand Charpentier
Cofounder, President & Chief Scientist

For some applications, it is not possible to run AI models on remote servers with large machines like A100, H100 because:
Remote communication is not allowed → E.g. General Data Protection Regulations (GDPR) imposes obligations onto sharing data.
Remote communication is not safe → E.g. Defenses applications work cannot risk transferring critical data.
Remote communication is not efficient →E.g. Remote/server communications are too slow.
Remote communication is not possible → Robotic applications do not have connection to remote servers.
In this case, Machine Learning practitioners have to find a solution to run AI models directly on edge devices like phones, single-board computers, or consumer GPUs. This is particularly challenging because while edge device have strict memory, speed, and energy constraints, modern AI models like Large Language Models (LLMs) have big resource requirements.
In this blog post, we considered (1) a wide range of devices, including small and large GPUs and non GPUs (see Tab. 1/2), and (2) a wide range of compression methods with a focus on quantization (see Sec. “How to compress LLMs for edge devices?”). We set up a wide range of deployment configurations, identify key productivity challenges based on software/hardware compatibility, and evaluate the final efficiency/quality performances of deployment configurations.
What are the challenges with deployment of LLMs on edge devices?
We consider a wide range of GPUs/non GPUs devices with different types, architectures, memory, and performance configurations.
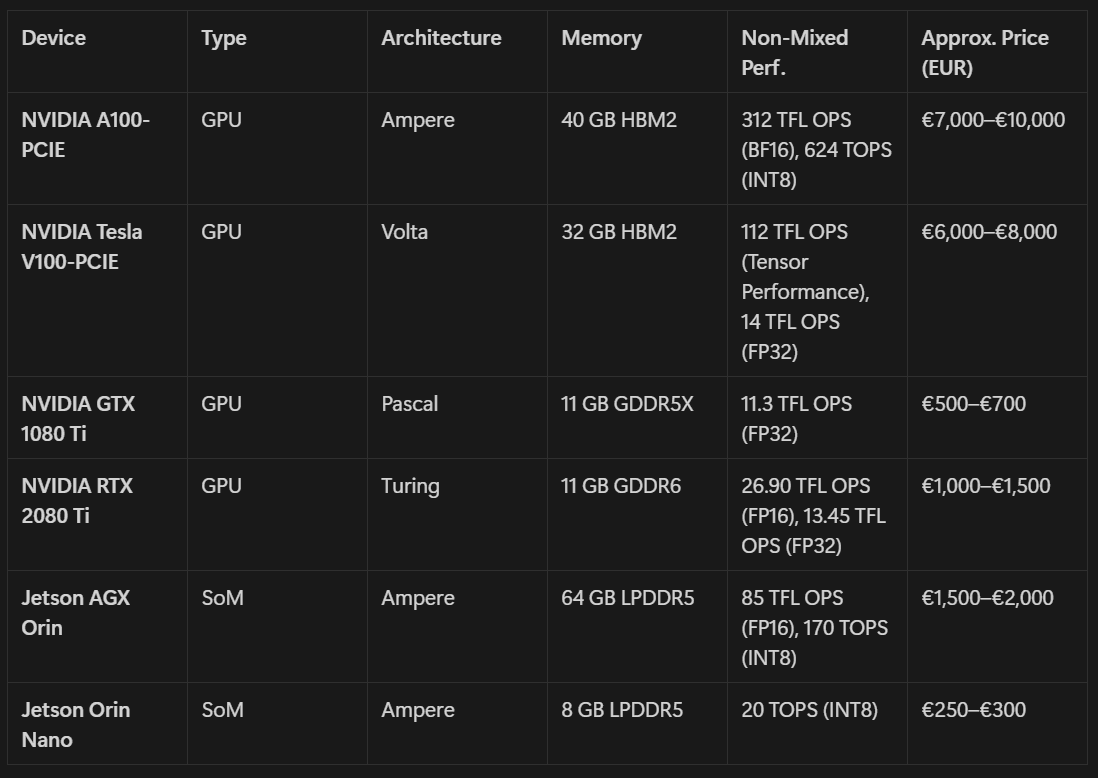
Tab. 1: GPU devices
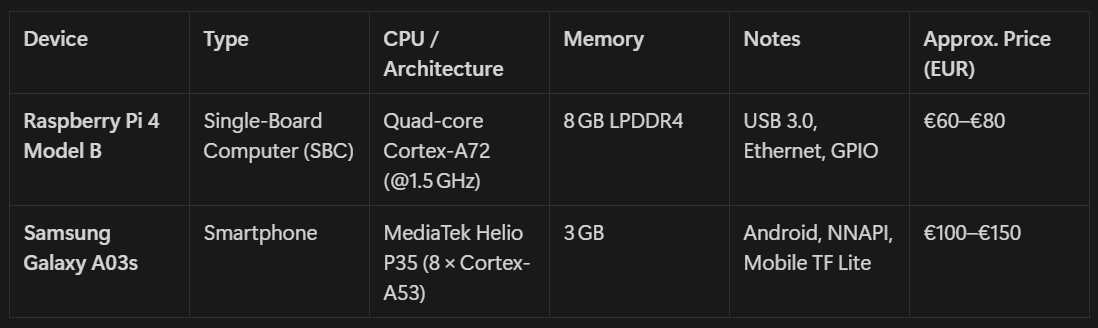
Tab. 2: Non-GPU devices
Deploying on edge comes with many challenges:
Memory Constraints: Edge devices often have limited memory to accommodate AI models. Devices like Samsung Galaxy A03s and NVIDIA Jetson Orin Nano have less than 8Gb to fit large models, which can requires hundreds of Gb.
Storage Limitations: Devices such as the Raspberry Pi 4 Model B and Samsung Galaxy A03s typically offer limited internal storage, posing challenges for storing large models and data files. Using external storage solutions, such as SSDs, can mitigate this issue; however, it adds complexity to the setup process.
Software/Hardware Compatibility: Ensuring compatibility between software (e.g., Hugging Face Transformers, PyTorch, CUDA, Quantization, operating systems, JetPack SDK) and hardware (e.g., built-in kernels, architecture) requires significant development time. First, it requires a lot of time to install and maintain consistent dependencies between packages. Second, even after setup, version mismatches of libraries can lead to suboptimal performance. This particularly impacts devices like Jetson, Raspberry, Samsung which are not as well-supported for AI deployment. E.g.
The installation instructions of JetPack SDK do not work reliably.
Not all devices support CUDA.
Specific packages, such as Hugging Face, are not well-supported.
Specific versions of OS are not well-supported.
The flashing device in recovery mode did not work reliably.
Efficiency/Quality Trade-off: Devices with constrained resources (e.g., Samsung Galaxy A03s) struggle with intensive models, often resulting in significant depletion of system resources during model execution. Optimizing performance can involve adjusting thread counts and employing lower-precision quantization (e.g., 8-bit or 4-bit), although this may necessitate trade-offs in model accuracy.
How to Compress LLMs for Edge Devices?
Many model compression techniques exist to reduce model size while maintaining acceptable performance. It includes pruning, knowledge distillation, and quantization. More specifically, quantization has demonstrated great performance by encoding model parameters with lower bit precisions. It can go from 32/16 bits down to 4 bits. In this blog, we consider popular quantization methods of them popular:
Quanto: It reduces the precision of model parameters and activations using learned scale and zero-point. It supports dynamic, per-tensor, and per-channel quantization.
Bits-and-Bytes (BnB) is a lightweight Python wrapper around CUDA custom functions. It focuses on treating outliers in matrix multiplications with high precision, while the rest are treated with low precision.
Generative Pre-trained Transformer Quantization (GPTQ): It iteratively quantizes a block of weight matrices and corrects quantization error by using second-order information.
Quantization Rotations (QuaRot): It is a preprocessing step that can be applied before the quantization step. It utilizes randomized Hadamard rotations to facilitate the quantization of weights and activations.
Activation-aware Weight Quantization (AWQ): It focuses on protecting salient weights during quantization (∼ 1% of the weights) identified by using the scale of their associated activations. Salient weights are scaled before quantization to preserve model accuracy while enabling low-bit quantization. It requires data during quantization.
Half-Quadratic Quantization (HQQ) formulates quantization parameters by minimizing a loss function with sparsity-promoting norms. It uses a Half-Quadratic solver to find optimal quantization parameters. It is data-free and fast to apply.
Llama.cpp: It is a framework for running large language models on diverse hardware with support for CPU+GPU hybrid inference. Provides quantization strategies from 1.5-bit to 8-bit integer precision.
You can access most of them with Pruna AI ;)
How well do LLMs on edge work?
We first start by comparing the quality of the compressed models to identify the best-performing compression algorithms. In particular, we compute the perplexity results on WikiText-2 and the perplexity on PTB for different quantization methods with context lengths of 8000 and 128 for the Meta-Llama-3-8B model. The benefit of 128 context length is that it requires much less memory to store the Key Value cache.
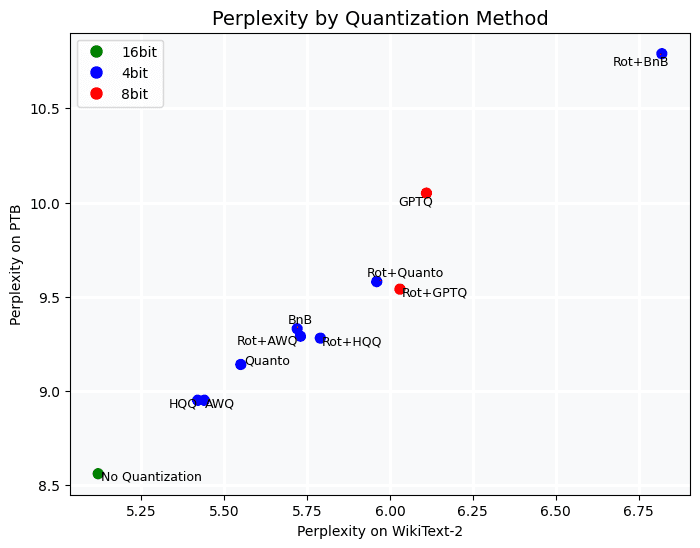

Key takeaways are that:
Not all compression methods are equivalent, with HQQ often yielding the best results.
Preprocessing steps, such as Hadamard rotations, do not guarantee higher performance.
It is possible to achieve predictions of comparable quality to the base model with 4 bits.
A larger context length is critical to achieving higher prediction quality. Indeed, for both wikitext and PTB, perplexity results are significantly lower with an 8000 context length compared to a 128 context length.
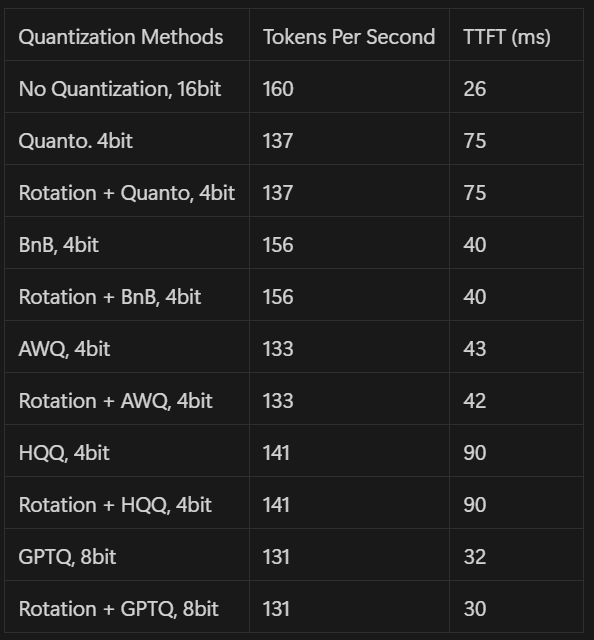
In addition to the perplexity, which indicates the quality of the results, we also measure the throughput using the number of Tokens per Second and the Time To First Token.
A100:
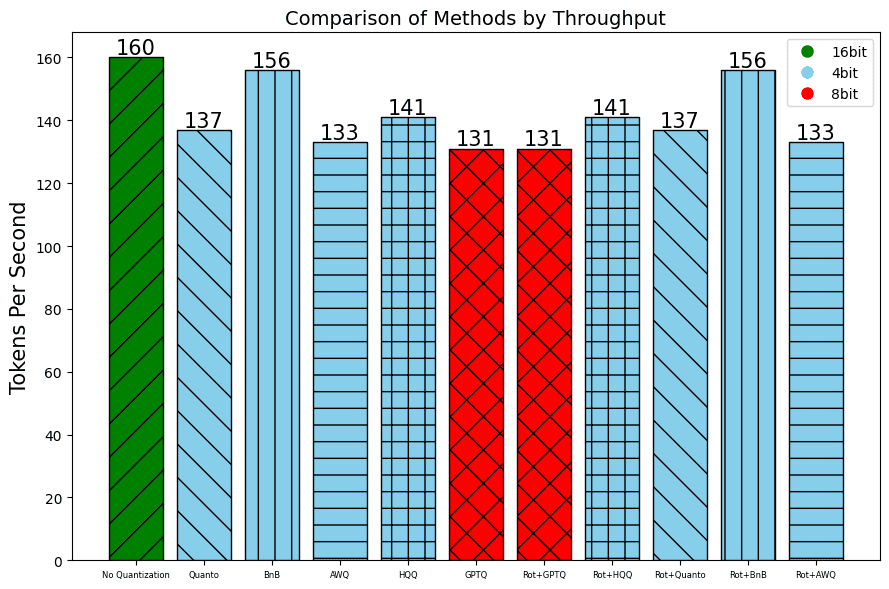

V100:

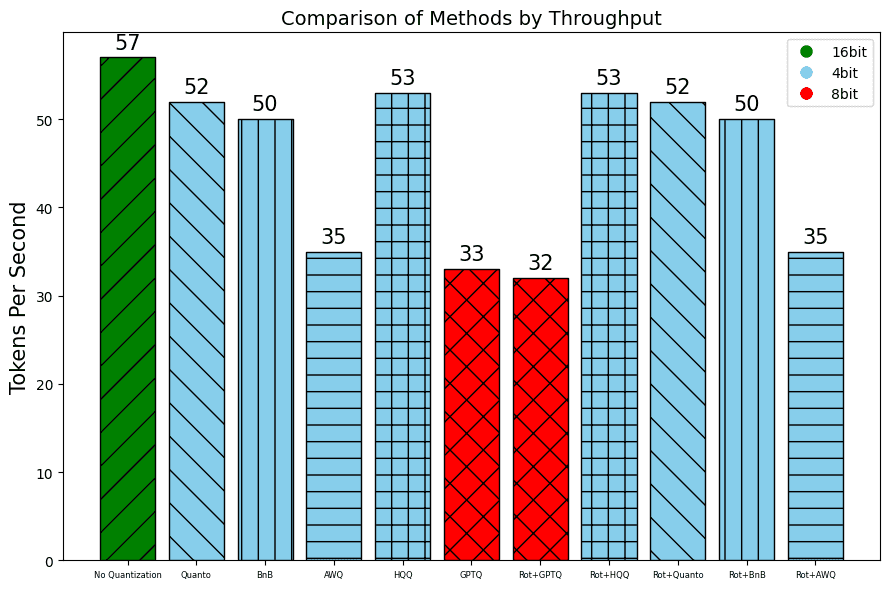
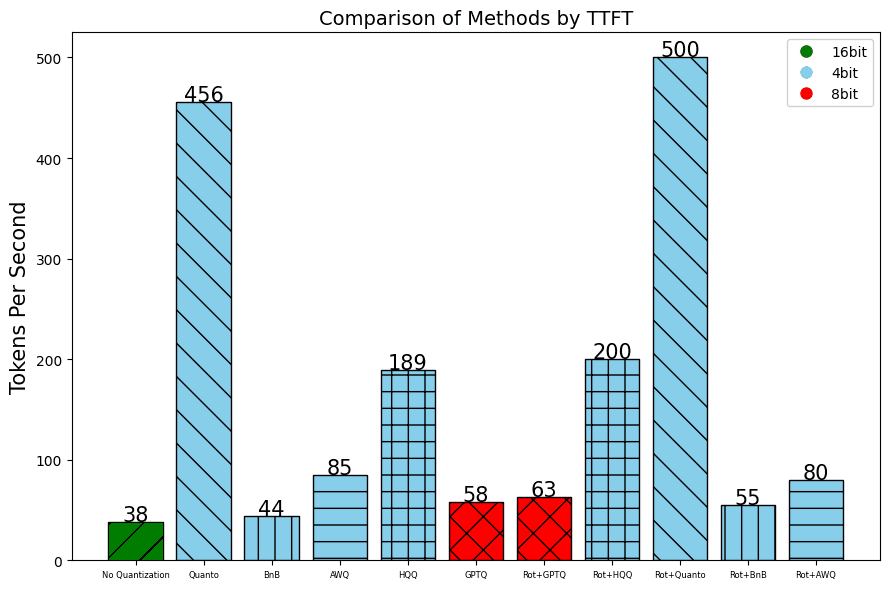
GTX 1080 Ti:
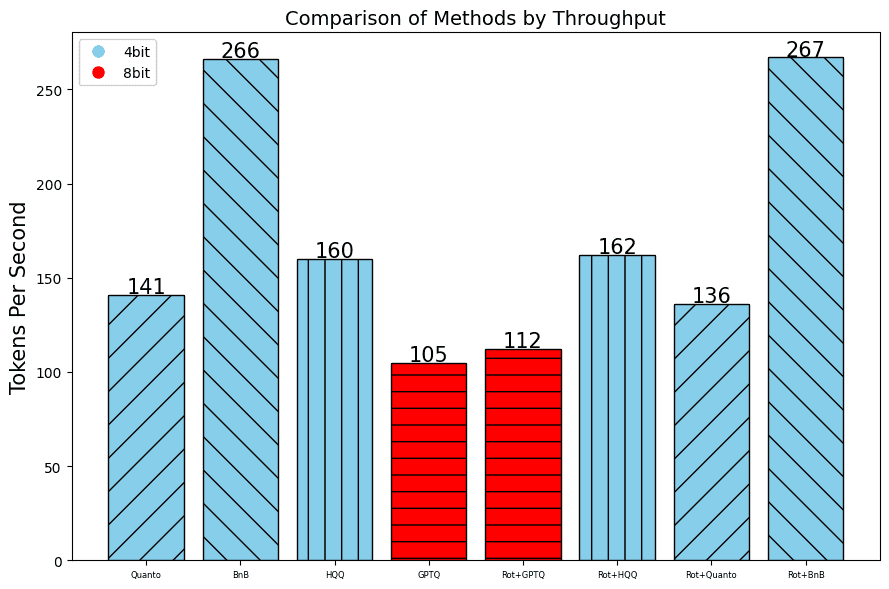
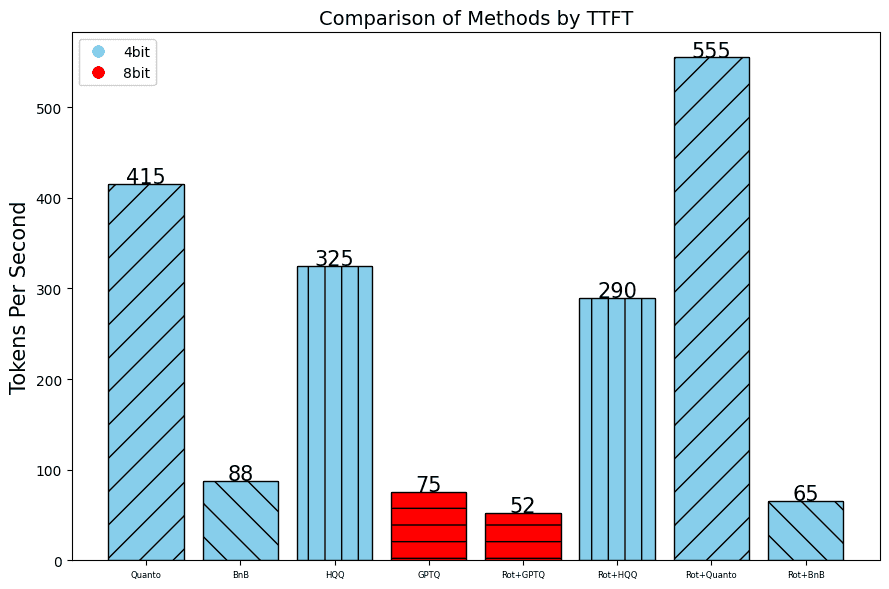
RTX 2080 Ti:



Jetson AGX Orin:
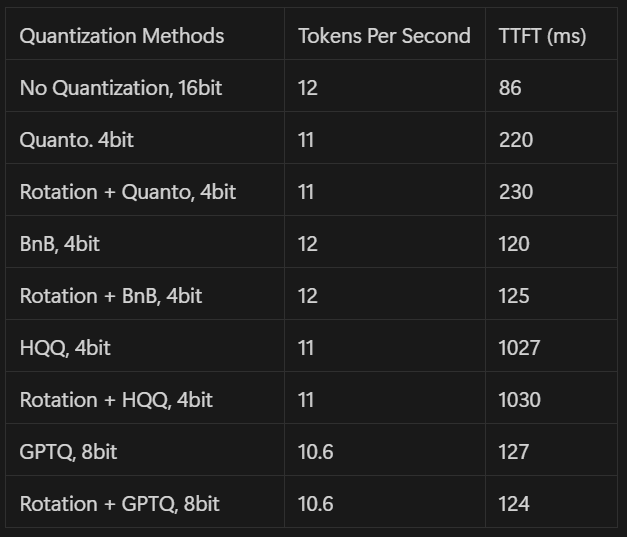
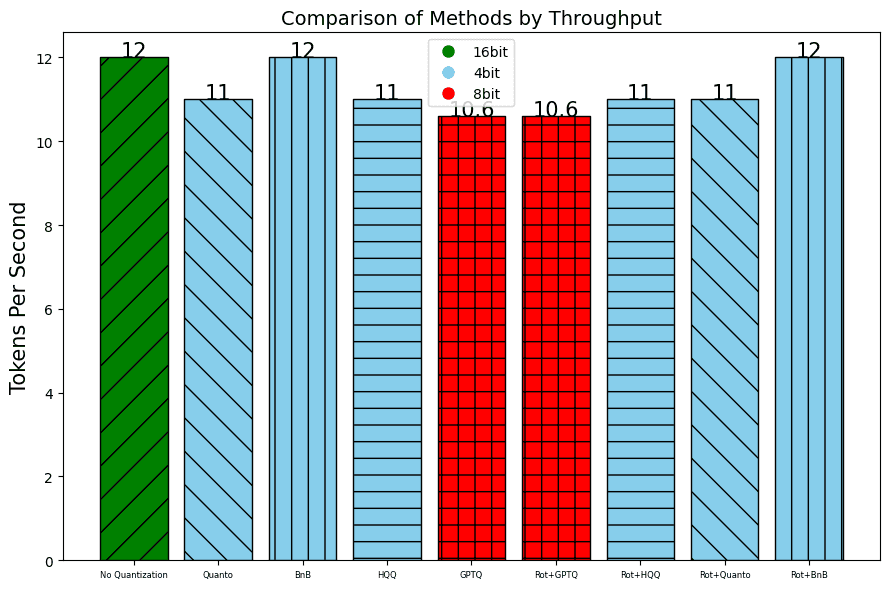
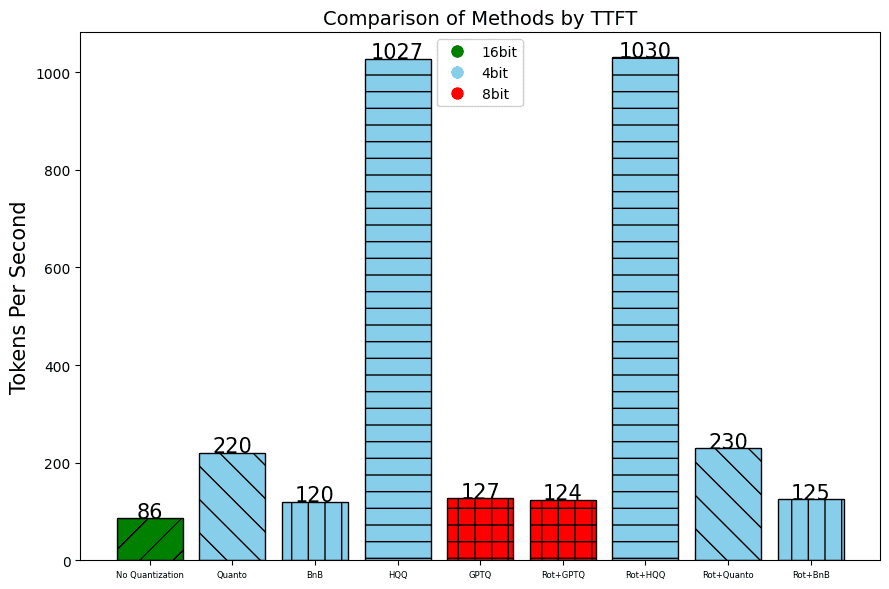
Jetson Orin Nano:

The results marked with a * were approximated.
CPU Devices
Raspberry Pi 4 Model B:

Samsung Galaxy A03s

The key takeaways are:
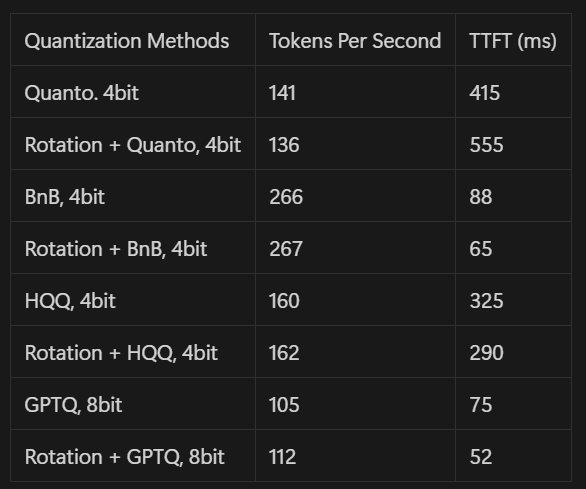
Quantization alone does not imply speedup. Indeed, quantized models require compilation with specific kernels to support efficient operations. Multiple compilation methods are available in Pruna AI documentation.
Many quantization methods do not natively support edge devices, particularly CPU edge devices, which are often not supported by quantization packages. Only Llama.cpp showed reasonable support for CPU edge devices.
It is possible to fit models on small devices, such as Raspberry Pi or smartphones with less than 8 GB of memory, while maintaining reasonable efficiency and quality at the edge (i.e., ~1 token per second and low perplexity).
Conclusion
Deploying AI models, such as LLMs, on edge devices presents significant challenges due to constraints including memory, storage, software compatibility, and performance optimization. However, through model compression techniques like quantization, it is possible to reduce the resource demands of these models, making them viable for deployment on smaller devices, such as smartphones, Raspberry Pi, and other edge hardware.
In this blog, we showed (1) development challenges in setting up and maintaining models on edge, and (2) explored various devices and quantization methods, highlighting the trade-offs between model quality and efficiency on edge.
Ready to take your edge AI deployment to the next level? At Pruna AI, we offer cutting-edge tools and resources to help you optimize and deploy AI models efficiently on a wide range of edge devices. Discover how our advanced compression techniques can make your models faster, smaller, and more efficient—start exploring today at Pruna AI.
・