Announcement
Accelerating FLUX.2 [flex]: Now Design x3 Faster

John Rachwan
Cofounder & CTO

Nils Fleischmann
ML Research Engineer

Johanna Sommer
ML Research Engineer

Sara Han Díaz
DevRel Engineer

David Berenstein
ML & DevRel Engineer

Bertrand Charpentier
Cofounder, President & Chief Scientist

When you’re designing, you need iteration. Iteration needs speed. FLUX.2 [flex] from Black Forest Labs delivers excellent results at text rendering and custom typography, ranking top in human preference rankings, but until recently, it came with a trade-off: latency.
We’ve been in touch with the Black Forest Labs team for a long time—well before this release. Long before FLUX.2 [flex], we were already optimizing the open-weight models they were publishing. Not because it was on a roadmap, but because we genuinely respected the work. BFL has consistently pushed the boundaries of generative image models, and whenever a new model dropped, our instinct was simple: “let’s see how far we can take it.”
Today, that long-running collaboration becomes official.
We worked together with Black Forest Labs to accelerate FLUX.2 [flex] to the next level. Now, FLUX.2 [flex] takes just ~13s per image, down from 48s before. It is ~3x faster!
This isn’t just an optimization win. It’s the result of two teams with very different, but highly complementary obsessions.
Black Forest Labs focuses on building flagship, high-quality foundation models that push the boundaries of what’s possible in image generation.
At Pruna, our obsession is different: making those models fast enough to be used in real-time creative workflows, without sacrificing quality.
When these two expectations meet, the impact is multiplicative.
You can try the official accelerated Black Forest Labs endpoint here: https://bfl.ai/models/flux-2

Why accelerate FLUX.2 [flex]?
We accelerate FLUX.2 [flex] to be faster and more efficient, reducing the time for image generation and editing.
Speed here isn’t about shaving off a few seconds. Going from ~48 seconds to ~13 seconds completely changes how people use the model. It stops feeling like a batch job and starts feeling interactive.
That means you can try more edits or style adjustments to texts, compare more typography variations, and refine toward the right result, without lowering the quality bar. This is especially critical for typography-heavy use cases, where iteration is everything and waiting a full minute for feedback simply breaks creative flow.
Ideal for:
Designers and creative teams seeking precise creative control.
Marketing and product teams creating on-brand, typography-heavy assets.
Developers working on product UIs
Use it for:
Brand and graphic design
Create beautiful and precise on-brand graphic design assets with clean, readable typography

Accurate long text
Generate your works with text. It adapts seamlessly to any style or layout you need. Modern, classic, handwritten, or dynamic 3D lettering.

Product UI prototyping with text components
Rapidly prototype product UIs with rich text components, accurate typography, and production-ready visuals.

How can you use FLUX.2 [flex]?
Try our demo: https://demo.pruna.ai/document-generator
The optimized model maintains all the capabilities of the original FLUX.2 [flex]:
Control over guidance scale
Ability to render text with high accuracy.
Supports up to 8 reference images for complex multi-image editing
More Speed. Same Quality
This is where the collaboration really matters. The objective wasn’t speed at any cost, but making FLUX.2 [flex] faster while keeping the quality that made it stand out in the first place.
After optimizing the model, we measured latency in an H200. In this setting, we reduced generation time from 48.53s per image to 13.11s, achieving 3.7x speedup. For image editing, we also reduced the time per image from 104.79 s to 27.63 s, resulting in a 3.85x improvement.
These results make it a very good, cost-efficient option for typography-heavy image generation, resulting in a better design experience and lower energy consumption.
GPUs | Mode | Output Size | Input Size | Base - Seconds/Image | Optimized - Seconds/Image |
|---|---|---|---|---|---|
1 | t2i | 1024x1024 | - | 48.53 | 13.11 |
2 | t2i | 1024x1024 | - | 26.97 | 7.75 |
4 | t2i | 1024x1024 | - | 15.02 | 4.98 |
1 | i2i | 1024x1024 | 1024x1024 | 104.79 | 27.63 |
2 | i2i | 1024x1024 | 1024x1024 | 57.41 | 15.92 |
4 | i2i | 1024x1024 | 1024x1024 | 31.40 | 9.94 |
Alongside latency, we evaluated output quality by comparing the optimized FLUX.2 [flex] with the top five models on an artificial analysis for the text & typography category across two text rendering benchmarks: LongTextBench and OneIG (text rendering subset). For the benchmarks, we used text word accuracy, which measures the % of errors relative to the total number of words. The table below provides an overview of the costs, speeds, and metric scores for each metric.
Model | Cost | Generation Speed | Long Text Bench | OneIG Text Rendering |
|---|---|---|---|---|
FLUX.2 [flex] fast | $0.050 | 14.09s | 0.8806 | 0.7666 |
FLUX.2 [max] | $0.070 | 38.20s | 0.8458 | 0.8230 |
FLUX.2 [flex] | $0.060 | 49.09s | 0.8681 | 0.7917 |
Nano Banana Pro | $0.150 | 23.05s | 0.8820 | 0.6843 |
Imagen 4 Ultra | $0.060 | 11.14s | 0.6049 | 0.5661 |
GPT Image 1.5 (high) | $0.136 | 45.71s | 0.9152 | 0.7675 |
Additionally, we’ve created some Pareto Front plots that emphasize that the optimized FLUX.2 [flex] is leading at all fronts in terms of speed vs quality for each benchmark, and it does so at the lowest overall cost of $0.05 per image!
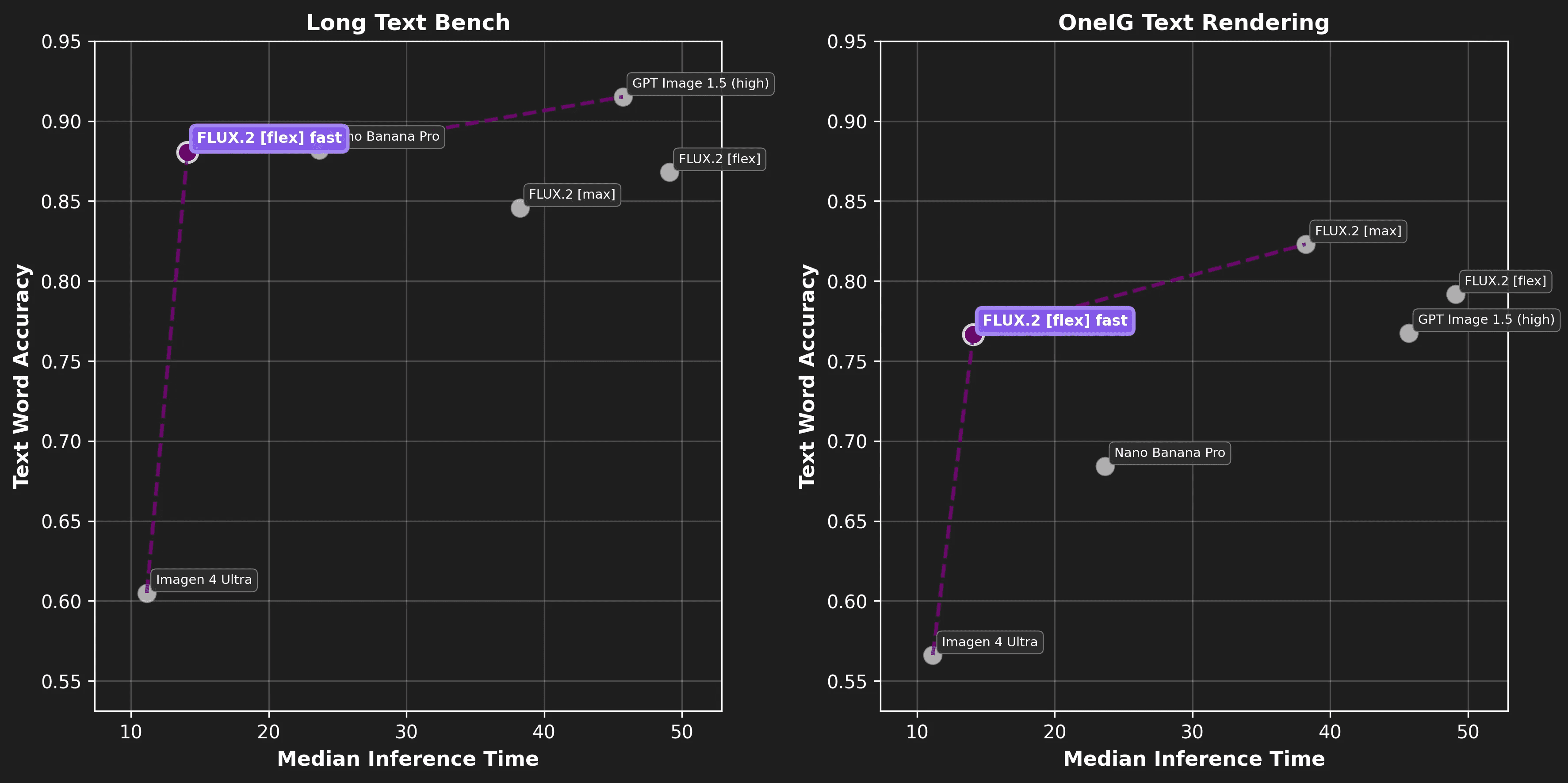
The numbers don’t lie and show how performant and quick the optimized model is, but let’s take a closer look at some of the images we’ve generated for each of the benchmarks.

As you can see, the results show that the speed improvements do not come at the expense of noticeable quality loss. FLUX.2 [flex] is the cheapest high-quality model on the market and also dominates the Pareto front in terms of speed-to-quality.
Try it now
FLUX.2 [flex] is now ideal to rapidly experiment with typography styles, copywriting ideas, and custom styles. Don’t let projects requiring highly accurate text rendering slow you down.
Try it in the Black Forest Labs endpoint: https://bfl.ai/models/flux-2
For us, this release is also a milestone. It’s the result of weeks of working side by side with the Black Forest Labs team: fast iterations, hands-on engineering, and the kind of constructive chaos that happens when two teams deeply care about what they’re building.
And if you’re a model creator facing similar challenges—great quality, but latency holding it back—we’re always eager to push further. Optimizing tough models is what we enjoy most.
・