Technical Article
・
Performance Models
Make your AI Image Generation x5.6 Faster: Pruna X ComfyUI

Angelos Nikitaras
ML Working Student

John Rachwan
Cofounder & CTO

Bertrand Charpentier
Cofounder, President & Chief Scientist

| ⚠️ There is a new version of the integration available on our blog page!
In today's rapidly evolving machine learning landscape, accessibility and efficiency are paramount. ComfyUI has revolutionized image generation by providing an intuitive, node-based interface that empowers users, from beginners to experts, to create powerful workflows to serve image generation models like Stable Diffusion or Flux. However, generation times can slow as models become more complex, increasing computational demands and costs.
Pruna tackles these challenges head-on by optimizing faster, smaller, cheaper, and greener models. Integrating Pruna's advanced compilation techniques directly into ComfyUI through the Pruna Compile node allows you to accelerate Stable Diffusion and Flux inference without sacrificing output quality. This means smoother, more efficient image generation—even as your models scale up.
In this blog post, you'll learn how to integrate the Pruna node into ComfyUI to supercharge your Stable Diffusion and Flux workflows. We'll walk you through each step and show you how these optimizations can lead to faster, more efficient image generation. For additional resources and updates, visit our repository, and if you find it helpful, consider giving it a star!
Getting Started
Setting up Pruna within ComfyUI is straightforward. With just a few steps, you can compile your Stable Diffusion or Flux models for faster inference inside the ComfyUI interface. Here's a quick guide to get started.
Step 1 - Prerequisites
Before proceeding, ensure you have created a conda environment with Python 3.10 and installed ComfyUI and Pruna. In particular:
Create a conda environment with Python 3.10, e.g. with
Generate a Pruna token, if you haven't yet obtained one.
Step 2 - Pruna node integration
With your environment prepared, you can integrate the Pruna node into your ComfyUI setup. Follow these steps to clone the repository and launch ComfyUI with the Pruna compilation node enabled:
Navigate to your ComfyUI installation’s custom_nodes folder:
Clone the ComfyUI_pruna repository:
Launch ComfyUI
After completing these steps, you should see the Pruna Compile node in the nodes menu under the Pruna category.
Pruna in Action: Accelerate Stable Diffusion and Flux
We offer two ComfyUI workflows to help you start with the Pruna node—one designed for Stable Diffusion and another for Flux.
You can load a workflow by dragging and dropping the provided JSON file into the ComfyUI window or clicking Open in the Workflow tab, as shown here.
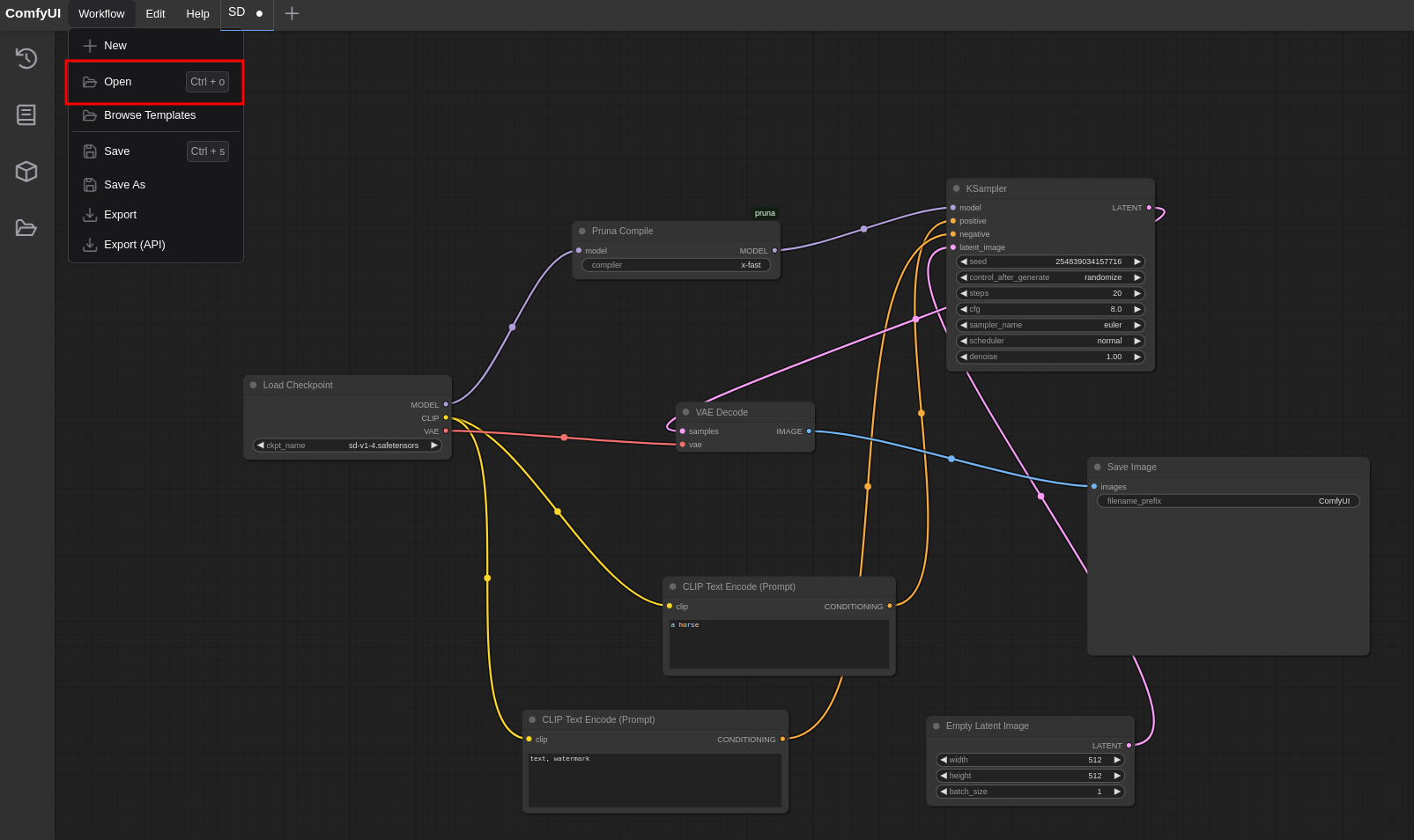{kind=link}
Our node currently supports two compilation modes: x-fast and torch_compile.
Example 1 - Stable Diffusion

In this example, we accelerate the inference of the Stable Diffusion v1.4 model. To get started, download the model and place it in the appropriate folder:
Download the model.
Place it in
<path_to_comfyui>/models/checkpoints.
Then, use the Stable Diffusion workflow as described above to generate images.
Example 2 - Flux

For Flux, the setup is a bit more involved due to its multi-component pipeline. You must download each model component individually to use the Flux workflow. Specifically:
For CLIP, download the clip_l.safetensors and t5xxl_fp16.safetensors files, and place them in
<path_to_comfyui>/models/clip/.For VAE, download the VAE model and place it in
<path_to_comfyui>/models/vae/.For the Flux model, download the weights and place them in
<path_to_comfyui>/models/diffusion_models/. If you cannot access the link, you can request model access on Hugging Face.
Now, load the Flux workflow, and you are ready to go!
Enjoy the speed-up!🎉
Benchmarks
We've put the Pruna Compile Node to the test to showcase its efficiency gains by comparing the base model with versions compiled using Pruna's x-fast and torch-compile compilers. Using an L40S Nvidia GPU, we measured two key performance metrics: iterations per second (as reported by ComfyUI) and the end-to-end time required to generate an image.
For Stable Diffusion, we observed an impressive 3.5x speedup in iterations per second using the x-fast compiler. While the gains for Flux are more modest, a 20% boost with torch_compile remains significant, especially since it comes with no degradation in output quality.


Closing Remarks
We’re excited to see how Pruna’s advanced compilation techniques empower ComfyUI to elevate your image generation workflows. Our benchmarks demonstrate significant performance gains without compromising quality, enabling you to push the boundaries of your creative projects 🚀
If you have any questions, feedback, or community discussions, feel free to join our Discord. You can also get help from our dedicated help desk channel.
Please open an issue in our repository for bug reports or technical issues.
・